Uno de los conceptos más importantes para entender un modelo de lenguaje es el de token. Cuando una persona escribe o lee, suele pensar en palabras, frases e ideas completas. El modelo, en cambio, trabaja con una unidad más básica de procesamiento: los tokens.
Un token no equivale necesariamente a una palabra completa. A veces puede ser una palabra entera, pero otras veces puede ser una parte de una palabra, un signo de puntuación, un número o una combinación corta de caracteres. El sistema fragmenta el texto en estas unidades porque así puede procesarlo de forma más manejable y estructurada.
Esto tiene consecuencias prácticas importantes. Cuando tú escribes una frase, el modelo no la “ve” exactamente como un humano que interpreta significado de manera directa. La convierte en una secuencia de tokens y opera sobre esas unidades. Eso afecta al coste computacional, a los límites del contexto y a la forma en que el sistema construye la respuesta.
Entender los tokens también ayuda a desmontar una idea equivocada: el modelo no procesa mágicamente “ideas enteras” de una sola vez. Trabaja sobre fragmentos que luego relaciona dentro de una secuencia más amplia. Esa lógica secuencial es una de las claves de su funcionamiento.
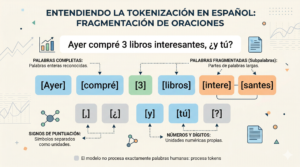
Un token puede coincidir con una palabra, pero también puede ser solo una parte, un signo o una unidad corta de texto.
El modelo trabaja con tokens porque necesita representar el lenguaje en una forma estructurada y computable.
Cuantos más tokens se usan, más recursos consume el sistema y más cerca se está del límite de contexto disponible.
Cuando una herramienta habla de “límite de texto”, por debajo casi siempre está hablando en realidad de tokens, no de palabras humanas en sentido estricto.